


Cray-1, il comodoso
Di Cray, in persona, se n'√® gi√Ý parlato nel mio ¬´libercolo¬ª. Nelle paginette dell‚ÄôUNIVAC/ERA 1103 e in quelle dei CDC 160 e 6600. Quest‚Äôultimo spesso indicato come il primo (super)computer basato su architettura RISC.
 Come dire che il buon Seymour Cray, nella storia informatica, non si trovava a passare lì per caso. Ovunque mettesse il becco, tirava fuori il meglio possibile, spesso anticipando di anni le (sue) nuove tecnologie. Zia Wiki lo definisce, oltre che padre del supercalcolo, come un «supercomputer architect che progettò una serie di macchine riconosciute come le più veloci al mondo per decenni … a lui è stato attribuito il merito di aver creato l'industria dei supercomputer». Ancora, Joel S. Birnbaum di Hewlett-Packard, disse: «molte delle cose che i computer ad alte prestazioni oggi fanno abitualmente, erano al limite estremo della credibilità quando Seymour le immaginava».
Come dire che il buon Seymour Cray, nella storia informatica, non si trovava a passare lì per caso. Ovunque mettesse il becco, tirava fuori il meglio possibile, spesso anticipando di anni le (sue) nuove tecnologie. Zia Wiki lo definisce, oltre che padre del supercalcolo, come un «supercomputer architect che progettò una serie di macchine riconosciute come le più veloci al mondo per decenni … a lui è stato attribuito il merito di aver creato l'industria dei supercomputer». Ancora, Joel S. Birnbaum di Hewlett-Packard, disse: «molte delle cose che i computer ad alte prestazioni oggi fanno abitualmente, erano al limite estremo della credibilità quando Seymour le immaginava».
Tra le sue intuizioni più alte, il fatto che la velocità di una CPU, in sé, non fosse sufficiente per realizzare nel suo insieme un sistema ad alte prestazioni. Il collo di bottiglia con la memoria e con l’I/O in genere, causa di molti problemi, doveva essere minimizzato, se non addirittura eliminato del tutto, per non affamare il processore in attesa dei dati. In altre parole, le sue, «Chiunque può costruire una CPU veloce. Il trucco è costruire un sistema veloce».
 Nel supercomputer Cray-1 venne implementata per la prima volta con successo l’architettura di calcolo vettoriale (SIMD, Single Instruction Multiple Datapath), in cui un array processor mette a disposizione istruzioni ottimizzate per operare in parallelo su dati disponibili in vettori… migliorando le prestazioni di calcolo… quando possibile… (tradotto: non tutto-tutto, si sa, è vettoriale o vettorializzabile).
Nel supercomputer Cray-1 venne implementata per la prima volta con successo l’architettura di calcolo vettoriale (SIMD, Single Instruction Multiple Datapath), in cui un array processor mette a disposizione istruzioni ottimizzate per operare in parallelo su dati disponibili in vettori… migliorando le prestazioni di calcolo… quando possibile… (tradotto: non tutto-tutto, si sa, è vettoriale o vettorializzabile).
Si contrappone alla più classica architettura scalare (SISD, Single Instruction Single Datapath) nella quale le istruzioni agiscono su singoli elementi di dati, come del resto era sempre stato fatto per decenni.
Non fu la prima volta in assoluto, ma negli esperimenti precedenti, che pure mettevano in pratica gli stessi concetti vettoriali, non si raggiungevano prestazioni altrettanto interessanti. Senza far nomi, come avveniva per lo STAR-100 di CDC, potenziale - ma soprattutto mancato - concorrente del Cray-1.
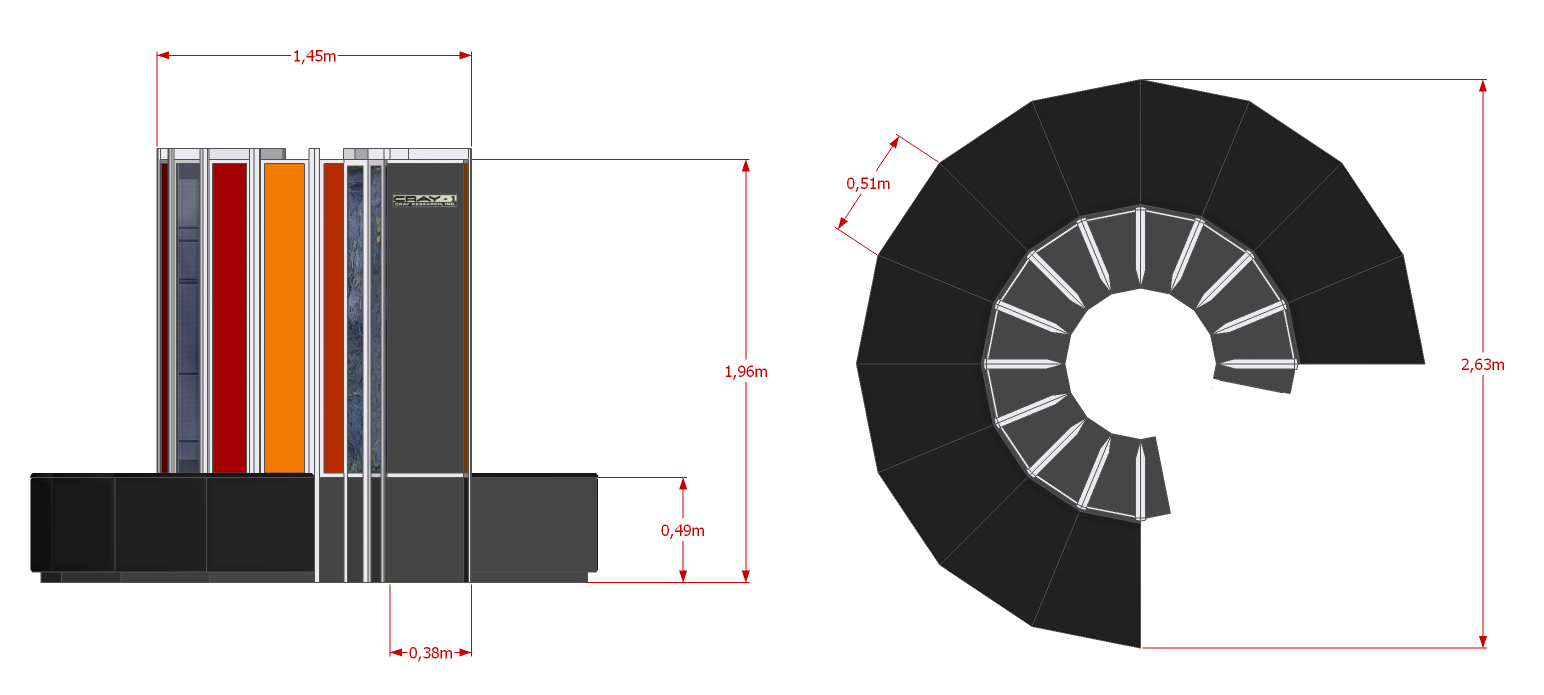 Con la sua forma ad anello (tre quarti di anello, 270°, con tanto di comoda panca sul bordo più esterno, sotto cui trovavano posto gli alimentatori) è stato uno dei pochi supercomputer riconoscibili al primo sguardo, ma non si trattava di una mera trovata estetica. La disposizione radiale delle varie (tante) schede elettroniche di cui era composta l’intera opera d’arte, serviva per ottimizzare i collegamenti, in particolare per rendere più brevi possibile quelli in cui serviva correre di più. Particolarmente curato, viste le temperature in gioco, era anche il raffreddamento dell’elettronica, basato su lastre di rame interposte tra le schede che conducevano il calore verso l’alto, dove veniva dissipato utilizzando condutture con freon liquido.
Con la sua forma ad anello (tre quarti di anello, 270°, con tanto di comoda panca sul bordo più esterno, sotto cui trovavano posto gli alimentatori) è stato uno dei pochi supercomputer riconoscibili al primo sguardo, ma non si trattava di una mera trovata estetica. La disposizione radiale delle varie (tante) schede elettroniche di cui era composta l’intera opera d’arte, serviva per ottimizzare i collegamenti, in particolare per rendere più brevi possibile quelli in cui serviva correre di più. Particolarmente curato, viste le temperature in gioco, era anche il raffreddamento dell’elettronica, basato su lastre di rame interposte tra le schede che conducevano il calore verso l’alto, dove veniva dissipato utilizzando condutture con freon liquido.
 Il suo clock a 80 MHz era in grado di macinare teoricamente fino a 160 MFLOPS e disponeva di una memoria centrale da BEN otto megabyte, più di preciso 1M words da 64 bit (più 8 per la parità). Se questi valori col senno di oggi possono quasi far tenerezza o sorridere (uno smartphone moderno non solo è migliaia di volte più veloce, ma sta in tasca acceso senza bisogno di freon) non era così in quegli anni. Basti pensare che nello stesso anno del lancio di Cray-1, l’Apple-1 - per usare la stessa grafia - aveva un clock ottanta volte inferiore e la sua memoria, una volta espansa a 8 KB era mille, anzi 1024, volte più piccola. Volendo fare un raffronto altrettanto impossibile con un dispositivo moderno, tra i più piccoli ed economici in circolazione, un Raspberry P3 di MFLOPS ne molla più di quattro volte tanto (quasi 650) rispetto al Cray-1 e quel che fa tanto riflettere è che questa schedina da pochi centimetri quadrati te la tirano dietro per una cinquantina d’euro o poco più. Che tempi, moderni!
Il suo clock a 80 MHz era in grado di macinare teoricamente fino a 160 MFLOPS e disponeva di una memoria centrale da BEN otto megabyte, più di preciso 1M words da 64 bit (più 8 per la parità). Se questi valori col senno di oggi possono quasi far tenerezza o sorridere (uno smartphone moderno non solo è migliaia di volte più veloce, ma sta in tasca acceso senza bisogno di freon) non era così in quegli anni. Basti pensare che nello stesso anno del lancio di Cray-1, l’Apple-1 - per usare la stessa grafia - aveva un clock ottanta volte inferiore e la sua memoria, una volta espansa a 8 KB era mille, anzi 1024, volte più piccola. Volendo fare un raffronto altrettanto impossibile con un dispositivo moderno, tra i più piccoli ed economici in circolazione, un Raspberry P3 di MFLOPS ne molla più di quattro volte tanto (quasi 650) rispetto al Cray-1 e quel che fa tanto riflettere è che questa schedina da pochi centimetri quadrati te la tirano dietro per una cinquantina d’euro o poco più. Che tempi, moderni!
AdP







